


 For example, when we generate analytic reports, we often need to put the daily business indicators for the week, the current month, and even a longer period of time in the horizontal direction according date, to conveniently compare.
For example, when we generate analytic reports, we often need to put the daily business indicators for the week, the current month, and even a longer period of time in the horizontal direction according date, to conveniently compare.
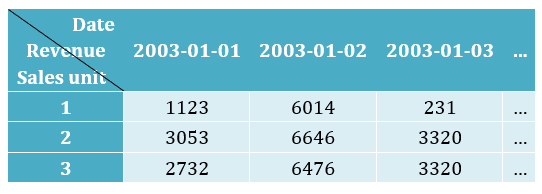 In an RDBMS database, the ANSI SQL for querying the results of the above table looks like the following :
In an RDBMS database, the ANSI SQL for querying the results of the above table looks like the following :
select call_center_key
,sum(decode(d.date, '2003-01-01'::date, sales_dollar_amount)) as "2003-0-01"
,sum(decode(d.date, '2003-01-02'::date, sales_dollar_amount)) as ,"2003-01-02"
sum(decode(d.date, '2003-01-03'::date, sales_dollar_amount)) as "2003-01-03"
--, ......
from online_sales.online_sales_fact f
inner join date_dimension d on f.sale_date_key = d.date_key
where d.date >= '2003-01-01' and d.date <= '2003-01-03'
group by call_center_key
order by 1 ;
This is a typical rows-to-columns transposing logic that requires the DECODE function or CASE WHEN branching of SQL, and group summing through the SUM function. If there are many columns to be transposed, many DECODE / CASE WHEN, and SUM functions or expressions are required, the SQL will be complicated, and slow down when analyzing huge volumes of data.
If we use the Vertica’s SDK to code a UDx, named PIVOT, to implement the rows-to-columns transposing logic, the above query can be rewritten as:
select call_center_key,
pivot(d.date::varchar, sales_dollar_amount using parameters columnsFilter = '2003-01-01,2003-01-02,2003-01-03') over(partition by call_center_key)
from online_sales.online_sales_fact f
inner join date_dimension d on f.sale_date_key = d.date_key
where d.date >= '2003-01-01' and d.date <= '2003-01-03'
order by call_center_key;
Vertica’s SDK provides sufficient abstraction for coding UDxs. Developers only need to fill in the real logic in the place required. For this example, Vertica’s SDK will push the rows with same call_center_key into the processPartition function UDTF PIVOT according to the declaration of the OVER(partition by call_center_key) clause. Rows with different call_center_key will execute processPartition function on different nodes of the cluster, and different threads in a node. Therefore, the processPartition function is required to support multi-thread reentrant and parallel execution.
Here our PIVOT UDx logic is simple and straightforward: use the first column of each row of the dataset from the SDK as the key, add the second column with the same key together; after the entire data set is processed, write the aggregated result back to the SDK.
virtual void processPartition(ServerInterface &srvInterface, PartitionReader &input_reader, PartitionWriter &output_writer)
{
// re-init buffer for sum
for(int idx = 0; idx < columnsCount; idx++)
measure[idx] = vfloat_null;
// sum 2nd parameter group by 1st parameter in each partition, considering NULL.
do {
// group by on 1st parameter
std::string gby = input_reader.getStringRef(0).str();
int idx = 0;
for(idx = 0; idx < columnsCount; idx++)
if( columnNames[idx].compare(gby) == 0 )
break;
// sum on 2nd parameter
vfloat value = input_reader.getFloatRef(1);
if (!vfloatIsNull(value))
{
if ( vfloatIsNull(measure[idx]) )
measure[idx] = value;
else
measure[idx] += value;
}
} while (input_reader.next());
// output
for(int idx = 0; idx < columnsCount; idx++)
output_writer.setFloat(idx, measure[idx]);
output_writer.next();
}
With powerful SDK of Vertica, the code is quickly finished, compiled and linked into a shared library, and finally deployed in Vertica using the following SQL:
CREATE LIBRARY pivot AS '/vertica_pivot/.libs/pivot.so';
CREATE TRANSFORM FUNCTION Pivot AS LANGUAGE ‘C++’ NAME ‘PivotFactory’ LIBRARY pivot fenced;
GRANT EXECUTE ON TRANSFORM FUNCTION Pivot () to PUBLIC;
If an issue is met in the upper coding process, you can debug and profile it with your preferred tools, such as gdb, valgrind, etc. For details about coding, debuging and profiling, please read the full post here.
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


