


This blog was written by Eugenia Moreno and Vicki Lindem.
More than once I have worked with customers who need to update a superprojection or create a new projection for a large fact table. It seems like a simple and easy process: just create a projection and perform a refresh.
However, refreshing projections for large fact tables can produce unwanted complications. In this blog, we’ll discuss these complications and how they can be remedied.
Why Refresh?
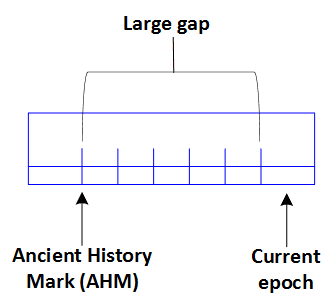
First, why do you need to perform a refresh? If you create a new projection for an existing table that contains data, that projection won’t be up-to-date until you perform a refresh. Additionally, until all the projections are refreshed, the Ancient History Mark (AHM) won’t advance. If the AHM doesn’t advance, the size of your epoch map, and the gap between your AHM and current epoch, increases. This means you are using more memory in the catalog because no data is being purged.
Complications for Large Tables
While refreshing your projections is necessary, the procedure can become problematic with projections of large fact tables.
First, you need sufficient disk storage. To refresh the projection, you need temp space so that Vertica can stage the new projection. You also need space to store the new projection data.
Even if you have space to spare, timing can be an issue. Refreshing projections of large tables can take hours. If a cluster failure occurs during the refresh, or if you run out of temp space, all the work already processed during the refresh will be lost.
Refresh Options
Luckily, you have a couple options when you want to refresh a projection, which we’ll cover in this blog. You can:
- Create a projection and execute the refresh meta-functions
- Use our recommended workaround for large fact tables
Generally, you refresh a projection by executing the START_REFRESH meta-function, which is a background process, or the REFRESH meta-function, which is a foreground process. However, as mentioned previously, this might take a long time or use too many resources if your table is large.
But how do you know if your projection warrants the first or second option?
Say you have a large fact table with existing projections. You want to create a new superprojection for this table, or perhaps combine two existing projections into a larger, updated superprojection.
First determine if taking the general approach is your best option. Start by considering the size of the projection you want to create.
View the PROJECTION_STORAGE system table to monitor the amount of disk storage used by current projections on each node.
=> SELECT node_name, projection_schema, projection_name, (SUM(used_bytes)/1024^3)::INT size_in_GB FROM projection_storage WHERE anchor_table_name ILIKE '%store_sales%' GROUP BY 1,2,3 ORDER BY 4 DESC LIMIT 20;
node_name | projection_schema | projection_name | size_in_GB
---------------+-------------------+------------------+----------
v_vdb_node0001 | copy_test | store_sales_test_load_b0 | 250
v_vdb_node0001 | copy_test | store_sales_test_load_b1 | 250
v_vdb_node0002 | copy_test | store_sales_test_load_b0 | 250
v_vdb_node0003 | copy_test | store_sales_test_load_b0 | 250
v_vdb_node0003 | copy_test | store_sales_test_load_b1 | 250
v_vdb_node0002 | copy_test | store_sales_test_load_b1 | 250
While this statement can’t actually tell you whether you have enough space to add a new projection to your large table or update a current one, it does give you an idea. For example, 250GB per node is large enough for us to think that a refresh process would take a long time.
Remedy
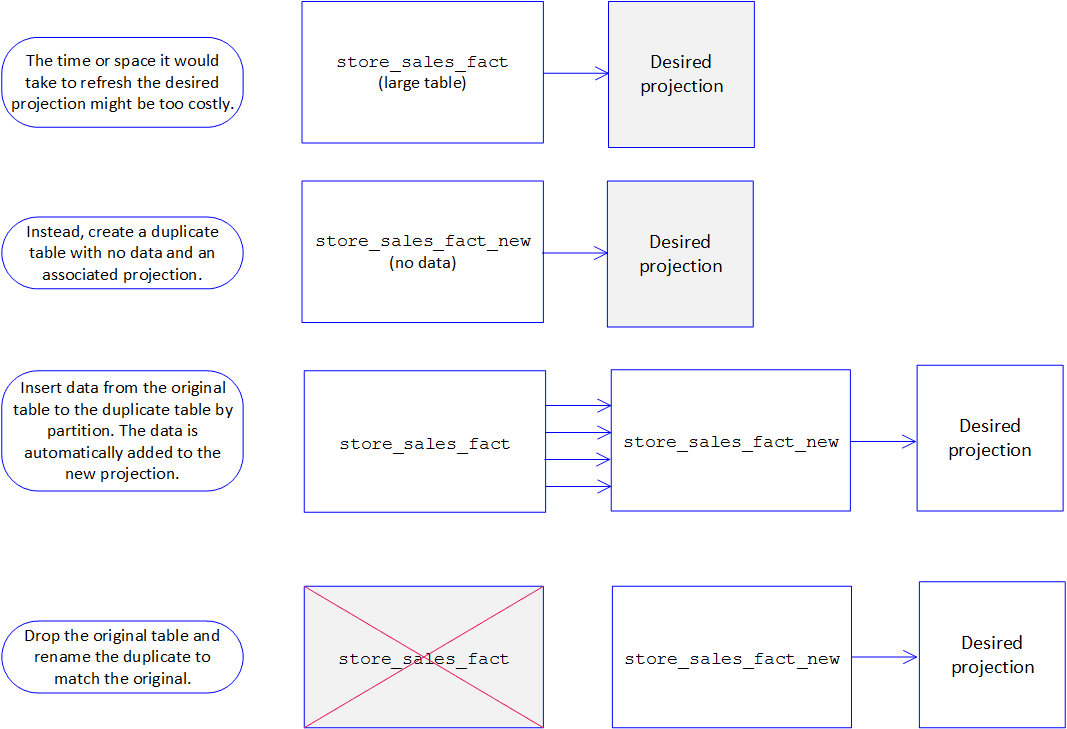
If your table is large and you estimate that creating a new projection on the large table and refreshing that projection will take long time, use this recommended workaround. In the workaround, you:
- Create a staging table with the new projection
- Copy the data into the new table
- Drop the old table
- Rename the new existing table.
By creating a new, empty table with the new desired projection, you no longer have to deal with a refresh; you can simply insert data from the original table into the new table, updating the new projection simultaneously. Your best choice is to insert the data from the existing table into the new table by partition. If you do full inserts partition by partition, Vertica will store the data in one ROS container and no Tuple Mover mergeout operation will be necessary after moving the data. You can also parallelize the number of batches to run at the same time so that you complete the process faster. When you do the insert, verify that it uses /*direct*/ to avoid a moveout operation.
Once the new table and projection contain the correct data, you can drop the old table and rename the new one with the old one’s name. See the following graphic for more details.
Example
Let’s use the workaround described previously to create a new projection for our large table store_sales_fact.
- Create an empty staging table using the CREATE TABLE statement with the LIKE clause:
=> CREATE TABLE store_sales_fact_new LIKE store_sales_fact; - Create the new superprojection for the new table:
=> CREATE PROJECTION store_sales_new_test
(
date_key,
product_key ENCODING RLE,
product_version ENCODING RLE,
...
)
AS
SELECT date_key,
product_key,
product_version,
.....
FROM store_sales_fact_new
ORDER BY product_key,
product_version,
store_key
SEGMENTED BY hash(product_key, product_version) ALL NODES KSAFE 1; - Insert data into the new table in batches.In this example, we export INSERT statements to a text file and then use a bash script to execute the inserts in parallel on different nodes.

- Verify data was copied correctly and completely:
=> SELECT COUNT(*) FROM <TABLE>_NEW;should be equal toSELECT COUNT(*) FROM <TABLE>; - Drop the old table and rename the new table:
=> DROP TABLE store_sales_fact;
=> ALTER TABLE store_sales_fact_new RENAME TO store_sales_fact;
Closing
As you can see, creating or updating a superprojection for a large table need not eat into your resources or time. By using our recommended workaround, you can save time and resources in just a couple steps. Of course, you can always use the handy refresh meta-functions as well.
About the Author
Sarah Lemaire
Manager, Vertica Documentation



